How slow is Node to Brotli decompress a file compared to not having to decompress?
January 19, 2024
3 comments Node, MacOSX, Linux
tl;dr; Not very slow.
At work, we have some very large .json that get included in a Docker image. The Node server then opens these files at runtime and displays certain data from that. To make the Docker image not too large, we compress these .json files at build-time. We compress the .json files with Brotli to make a .json.br file. Then, in the Node server code, we read them in and decompress them at runtime. It looks something like this:
export function readCompressedJsonFile(xpath) {
return JSON.parse(brotliDecompressSync(fs.readFileSync(xpath)))
}
The advantage of compressing them first, at build time, which is GitHub Actions, is that the Docker image becomes smaller which is advantageous when shipping that image to a registry and asking Azure App Service to deploy it. But I was wondering, is this a smart trade-off? In a sense, why compromise on runtime (which faces users) to save time and resources at build-time, which is mostly done away from the eyes of users? The question was; how much overhead is it to have to decompress the files after its data has been read from disk to memory?
The benchmark
The files I test with are as follows:
❯ ls -lh pageinfo*
-rw-r--r-- 1 peterbe staff 2.5M Jan 19 08:48 pageinfo-en-ja-es.json
-rw-r--r-- 1 peterbe staff 293K Jan 19 08:48 pageinfo-en-ja-es.json.br
-rw-r--r-- 1 peterbe staff 805K Jan 19 08:48 pageinfo-en.json
-rw-r--r-- 1 peterbe staff 100K Jan 19 08:48 pageinfo-en.json.br
There are 2 groups:
- Only English (
en) - 3 times larger because it has English, Japanese, and Spanish
And for each file, you can see the effect of having compressed them with Brotli.
- The smaller JSON file compresses 8x
- The larger JSON file compresses 9x
Here's the benchmark code:
import fs from "fs";
import { brotliDecompressSync } from "zlib";
import { Bench } from "tinybench";
const JSON_FILE = "pageinfo-en.json";
const BROTLI_JSON_FILE = "pageinfo-en.json.br";
const LARGE_JSON_FILE = "pageinfo-en-ja-es.json";
const BROTLI_LARGE_JSON_FILE = "pageinfo-en-ja-es.json.br";
function f1() {
const data = fs.readFileSync(JSON_FILE, "utf8");
return Object.keys(JSON.parse(data)).length;
}
function f2() {
const data = brotliDecompressSync(fs.readFileSync(BROTLI_JSON_FILE));
return Object.keys(JSON.parse(data)).length;
}
function f3() {
const data = fs.readFileSync(LARGE_JSON_FILE, "utf8");
return Object.keys(JSON.parse(data)).length;
}
function f4() {
const data = brotliDecompressSync(fs.readFileSync(BROTLI_LARGE_JSON_FILE));
return Object.keys(JSON.parse(data)).length;
}
console.assert(f1() === 2633);
console.assert(f2() === 2633);
console.assert(f3() === 7767);
console.assert(f4() === 7767);
const bench = new Bench({ time: 100 });
bench.add("f1", f1).add("f2", f2).add("f3", f3).add("f4", f4);
await bench.warmup(); // make results more reliable, ref: https://github.com/tinylibs/tinybench/pull/50
await bench.run();
console.table(bench.table());
Here's the output from tinybench:
┌─────────┬───────────┬─────────┬────────────────────┬──────────┬─────────┐ │ (index) │ Task Name │ ops/sec │ Average Time (ns) │ Margin │ Samples │ ├─────────┼───────────┼─────────┼────────────────────┼──────────┼─────────┤ │ 0 │ 'f1' │ '179' │ 5563384.55941942 │ '±6.23%' │ 18 │ │ 1 │ 'f2' │ '150' │ 6627033.621072769 │ '±7.56%' │ 16 │ │ 2 │ 'f3' │ '50' │ 19906517.219543457 │ '±3.61%' │ 10 │ │ 3 │ 'f4' │ '44' │ 22339166.87965393 │ '±3.43%' │ 10 │ └─────────┴───────────┴─────────┴────────────────────┴──────────┴─────────┘
Note, this benchmark is done on my 2019 Intel MacBook Pro. This disk is not what we get from the Apline Docker image (running inside Azure App Service). To test that would be a different story. But, at least we can test it in Docker locally.
I created a Dockerfile that contains...
ARG NODE_VERSION=20.10.0
FROM node:${NODE_VERSION}-alpine
and run the same benchmark in there by running docker composite up --build. The results are:
┌─────────┬───────────┬─────────┬────────────────────┬──────────┬─────────┐ │ (index) │ Task Name │ ops/sec │ Average Time (ns) │ Margin │ Samples │ ├─────────┼───────────┼─────────┼────────────────────┼──────────┼─────────┤ │ 0 │ 'f1' │ '151' │ 6602581.124978315 │ '±1.98%' │ 16 │ │ 1 │ 'f2' │ '112' │ 8890548.4166656 │ '±7.42%' │ 12 │ │ 2 │ 'f3' │ '44' │ 22561206.40002191 │ '±1.95%' │ 10 │ │ 3 │ 'f4' │ '37' │ 26979896.599974018 │ '±1.07%' │ 10 │ └─────────┴───────────┴─────────┴────────────────────┴──────────┴─────────┘
Analysis/Conclusion
First, focussing on the smaller file: Processing the .json is 25% faster than the .json.br file
Then, the larger file: Processing the .json is 16% faster than the .json.br file
So that's what we're paying for a smaller Docker image. Depending on the size of the .json file, your app runs ~20% slower at this operation. But remember, as a file on disk (in the Docker image), it's ~8x smaller.
I think, in conclusion: It's a small price to pay. It's worth doing. Your context depends.
Keep in mind the numbers there to process that 300KB pageinfo-en-ja-es.json.br file, it was able to do that 37 times in one second. That means it took 27 milliseconds to process that file!
The caveats
To repeat, what was mentioned above: This was run in my Intel MacBook Pro. It's likely to behave differently in a real Docker image running inside Azure.
The thing that I wonder the most about is arguably something that actually doesn't matter. 🙃
When you ask it to read in a .json.br file, there's less data to ask from the disk into memory. That's a win. You lose on CPU work but gain on disk I/O. But only the end net result matters so in a sense that's just an "implementation detail".
Admittedly, I don't know if the macOS or the Linux kernel does things with caching the layer between the physical disk and RAM for these files. The benchmark effectively asks "Hey, hard disk, please send me a file called ..." and this could be cached in some layer beyond my knowledge/comprehension. In a real production server, this only happens once because once the whole file is read, decompressed, and parsed, it won't be asked for again. Like, ever. But in a benchmark, perhaps the very first ask of the file is slower and all the other runs are unrealistically faster.
Feel free to clone https://github.com/peterbe/reading-json-files and mess around to run your own tests. Perhaps see what effect async can have. Or perhaps try it with Bun and it's file system API.
fnm is much faster than nvm.
December 28, 2023
1 comment Node, MacOSX
I used nvm so that when I cd into a different repo, it would automatically load the appropriate version of node (and npm). Simply by doing cd ~/dev/remix-peterbecom, for example, it would make the node executable to become whatever the value of the optional file ~/dev/remix-peterbecom/.nvmrc's content. For example v18.19.0.
And nvm helps you install and get your hands on various versions of node to be able to switch between. Much more fine-tuned than brew install node20.
The problem with all of this is that it's horribly slow. Opening a new terminal is annoyingly slow because that triggers the entering of a directory and nvm slowly does what it does.
The solution is to ditch it and go for fnm instead. Please, if you're an nvm user, do consider making this same jump in 2024.
Installation
Running curl -fsSL https://fnm.vercel.app/install | bash basically does some brew install and figuring out what shell you have and editing your shell config. By default, it put:
export PATH="/Users/peterbe/Library/Application Support/fnm:$PATH"
eval "`fnm env`"
...into my .zshrc file. But, I later learned you need to edit the last line to:
-eval "`fnm env`"
+eval "$(fnm env --use-on-cd)"
so that it automatically activates immediately after you've cd'ed into a directory.
If you had direnv to do this, get rid of that. fmn does not need direnv.
Now, create a fresh new terminal and it should be set up, including tab completion. You can test it by typing fnm[TAB]. You'll see:
❯ fnm
alias -- Alias a version to a common name
completions -- Print shell completions to stdout
current -- Print the current Node.js version
default -- Set a version as the default version
env -- Print and set up required environment variables for fnm
exec -- Run a command within fnm context
help -- Print this message or the help of the given subcommand(s)
install -- Install a new Node.js version
list ls -- List all locally installed Node.js versions
list-remote ls-remote -- List all remote Node.js versions
unalias -- Remove an alias definition
uninstall -- Uninstall a Node.js version
use -- Change Node.js version
Usage
If you had .nvmrc files sprinkled about from before, fnm will read those. If you cd into a directory, that contains .nvmrc, whose version fnm hasn't installed, yet, you get this:
❯ cd ~/dev/GROCER/groce/
Can't find an installed Node version matching v16.14.2.
Do you want to install it? answer [y/N]:
Neat!
But if you want to set it up from scratch, go into your directory of choice, type:
fnm ls-remote
...to see what versions of node you can install. Suppose you want v20.10.0 in the current directory do these two commands:
fnm install v20.10.0
echo v20.10.0 > .node-version
That's it!
Notes
-
I prefer that
.node-versionconvention so I've been going around doingmv .nvmrc .node-versionin various projects -
fnm lsis handy to see which ones you've installed already -
Suppose you want to temporarily use a specific version, simply type
fnm use v16.20.2for example -
I heard good things about volta too but got a bit nervous when I found out it gets involved in installing packages and not just versions of
node. -
fnmdoes not concern itself with upgrading yournodeversions. To get the latest version ofnodev21.x, it's up to you to checkfnm ls-remoteand compare that with the output ofnode --version.
Comparing different efforts with WebP in Sharp
October 5, 2023
0 comments Node, JavaScript
When you, in a Node program, use sharp to convert an image buffer to a WebP buffer, you have an option of effort. The higher the number the longer it takes but the image it produces is smaller on disk.
I wanted to put some realistic numbers for this, so I wrote a benchmark, run on my Intel MacbookPro.
The benchmark
It looks like this:
async function e6() {
return await f("screenshot-1000.png", 6);
}
async function e5() {
return await f("screenshot-1000.png", 5);
}
async function e4() {
return await f("screenshot-1000.png", 4);
}
async function e3() {
return await f("screenshot-1000.png", 3);
}
async function e2() {
return await f("screenshot-1000.png", 2);
}
async function e1() {
return await f("screenshot-1000.png", 1);
}
async function e0() {
return await f("screenshot-1000.png", 0);
}
async function f(fp, effort) {
const originalBuffer = await fs.readFile(fp);
const image = sharp(originalBuffer);
const { width } = await image.metadata();
const buffer = await image.webp({ effort }).toBuffer();
return [buffer.length, width, { effort }];
}
Then, I ran each function in serial and measured how long it took. Then, do that whole thing 15 times. So, in total, each function is executed 15 times. The numbers are collected and the median (P50) is reported.
A 2000x2000 pixel PNG image
1. e0: 191ms 235KB 2. e1: 340.5ms 208KB 3. e2: 369ms 198KB 4. e3: 485.5ms 193KB 5. e4: 587ms 177KB 6. e5: 695.5ms 177KB 7. e6: 4811.5ms 142KB
What it means is that if you use {effort: 6} the conversion of a 2000x2000 PNG took 4.8 seconds but the resulting WebP buffer became 142KB instead of the least effort which made it 235 KB.
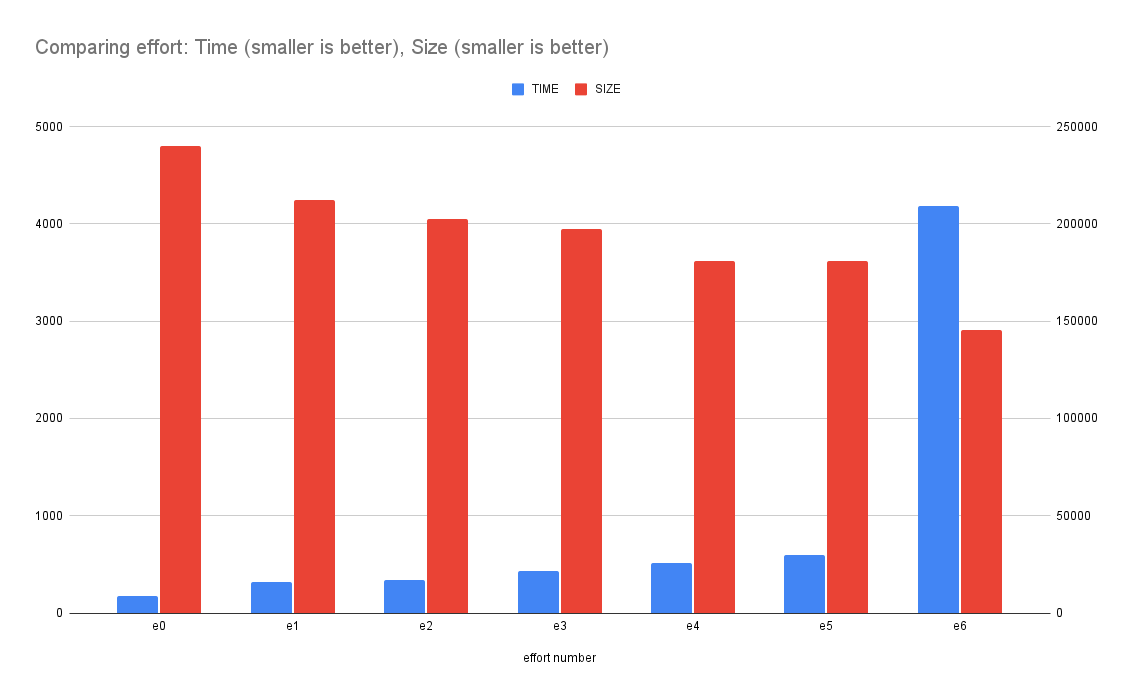
This graph demonstrates how the (blue) time goes up the more effort you put in. And how the final size (red) goes down the more effort you put in.
A 1000x1000 pixel PNG image
1. e0: 54ms 70KB 2. e1: 60ms 66KB 3. e2: 65ms 61KB 4. e3: 96ms 59KB 5. e4: 169ms 53KB 6. e5: 193ms 53KB 7. e6: 1466ms 51KB
A 500x500 pixel PNG image
1. e0: 24ms 23KB 2. e1: 26ms 21KB 3. e2: 28ms 20KB 4. e3: 37ms 19KB 5. e4: 57ms 18KB 6. e5: 66ms 18KB 7. e6: 556ms 18KB
Conclusion
Up to you but clearly, {effort: 6} is to be avoided if you're worried about it taking a huge amount of time to make the conversion.
Perhaps the takeaway is; that if you run these operations in the build step such that you don't have to ever do it again, it's worth the maximum effort. Beyond that, find a sweet spot for your particular environment and challenge.
Introducing hylite - a Node code-syntax-to-HTML highlighter written in Bun
October 3, 2023
0 comments Node, Bun, JavaScript
hylite is a command line tool for syntax highlight code into HTML. You feed it a file or some snippet of code (plus what language it is) and it returns a string of HTML.
Suppose you have:
❯ cat example.py
# This is example.py
def hello():
return "world"
When you run this through hylite you get:
❯ npx hylite example.py
<span class="hljs-keyword">def</span> <span class="hljs-title function_">hello</span>():
<span class="hljs-keyword">return</span> <span class="hljs-string">"world"</span>
Now, if installed with the necessary CSS, it can finally render this:
# This is example.py
def hello():
return "world"
(Note: At the time of writing this, npx hylite --list-css or npx hylite --css don't work unless you've git clone the github.com/peterbe/hylite repo)
How I use it
This originated because I loved how highlight.js works. It supports numerous languages, can even guess the language, is fast as heck, and the HTML output is compact.
Originally, my personal website, whose backend is in Python/Django, was using Pygments to do the syntax highlighting. The problem with that is it doesn't support JSX (or TSX). For example:
export function Bell({ color }: {color: string}) {
return <div style={{ backgroundColor: color }}>Ding!</div>
}
The problem is that Python != Node so to call out to hylite I use a sub-process. At the moment, I can't use bunx or npx because that depends on $PATH and stuff that the server doesn't have. Here's how I call hylite from Python:
command = settings.HYLITE_COMMAND.split()
assert language
command.extend(["--language", language, "--wrapped"])
process = subprocess.Popen(
command,
stdin=subprocess.PIPE,
stdout=subprocess.PIPE,
stderr=subprocess.PIPE,
text=True,
cwd=settings.HYLITE_DIRECTORY,
)
process.stdin.write(code)
output, error = process.communicate()
The settings are:
HYLITE_DIRECTORY = "/home/django/hylite"
HYLITE_COMMAND = "node dist/index.js"
How I built hylite
What's different about hylite compared to other JavaScript packages and CLIs like this is that the development requires Bun. It's lovely because it has a built-in test runner, TypeScript transpiler, and it's just so lovely fast at starting for anything you do with it.
In my current view, I see Bun as an equivalent of TypeScript. It's convenient when developing but once stripped away it's just good old JavaScript and you don't have to worry about compatibility.
So I use bun for manual testing like bun run src/index.ts < foo.go but when it comes time to ship, I run bun run build (which executes, with bun, the src/build.ts) which then builds a dist/index.js file which you can run with either node or bun anywhere.
By the way, the README as a section on Benchmarking. It concludes two things:
node dist/index.jshas the same performance asbun run dist/index.jsbunx hyliteis 7x times faster thannpx hylitebut it's bullcrap becausebunxdoesn't check the network if there's a new version (...until you restart your computer)
Shallow clone vs. deep clone, in Node, with benchmark
September 29, 2023
0 comments Node, JavaScript
A very common way to create a "copy" of an Object in JavaScript is to copy all things from one object into an empty one. Example:
const original = {foo: "Foo"}
const copy = Object.assign({}, original)
copy.foo = "Bar"
console.log([original.foo, copy.foo])
This outputs
[ 'Foo', 'Bar' ]
Obviously the problem with this is that it's a shallow copy, best demonstrated with an example:
const original = { names: ["Peter"] }
const copy = Object.assign({}, original)
copy.names.push("Tucker")
console.log([original.names, copy.names])
This outputs:
[ [ 'Peter', 'Tucker' ], [ 'Peter', 'Tucker' ] ]
which is arguably counter-intuitive. Especially since the variable was named "copy".
Generally, I think Object.assign({}, someThing) is often a red flag because if not today, maybe in some future the thing you're copying might have mutables within.
The "solution" is to use structuredClone which has been available since Node 16. Actually, it was introduced within minor releases of Node 16, so be a little bit careful if you're still on Node 16.
Same example:
const original = { names: ["Peter"] };
// const copy = Object.assign({}, original);
const copy = structuredClone(original);
copy.names.push("Tucker");
console.log([original.names, copy.names]);
This outputs:
[ [ 'Peter' ], [ 'Peter', 'Tucker' ] ]
Another deep copy solution is to turn the object into a string, using JSON.stringify and turn it back into a (deeply copied) object using JSON.parse. It works like structuredClone but full of caveats such as unpredictable precision loss on floating point numbers, and not to mention date objects ceasing to be date objects but instead becoming strings.
Benchmark
Given how much "better" structuredClone is in that it's more intuitive and therefore less dangerous for sneaky nested mutation bugs. Is it fast? Before even running a benchmark; no, structuredClone is slower than Object.assign({}, ...) because of course. It does more! Perhaps the question should be: how much slower is structuredClone? Here's my benchmark code:
import fs from "fs"
import assert from "assert"
import Benchmark from "benchmark"
const obj = JSON.parse(fs.readFileSync("package-lock.json", "utf8"))
function f1() {
const copy = Object.assign({}, obj)
copy.name = "else"
assert(copy.name !== obj.name)
}
function f2() {
const copy = structuredClone(obj)
copy.name = "else"
assert(copy.name !== obj.name)
}
function f3() {
const copy = JSON.parse(JSON.stringify(obj))
copy.name = "else"
assert(copy.name !== obj.name)
}
new Benchmark.Suite()
.add("f1", f1)
.add("f2", f2)
.add("f3", f3)
.on("cycle", (event) => {
console.log(String(event.target))
})
.on("complete", function () {
console.log("Fastest is " + this.filter("fastest").map("name"))
})
.run()
The results:
❯ node assign-or-clone.js f1 x 8,057,542 ops/sec ±0.84% (93 runs sampled) f2 x 37,245 ops/sec ±0.68% (94 runs sampled) f3 x 37,978 ops/sec ±0.85% (92 runs sampled) Fastest is f1
In other words, Object.assign({}, ...) is 200 times faster than structuredClone.
By the way, I re-ran the benchmark with a much smaller object (using the package.json instead of the package-lock.json) and then Object.assign({}, ...) is only 20 times faster.
Mind you! They're both ridiculously fast in the grand scheme of things.
If you do this...
for (let i = 0; i < 10; i++) {
console.time("f1")
f1()
console.timeEnd("f1")
console.time("f2")
f2()
console.timeEnd("f2")
console.time("f3")
f3()
console.timeEnd("f3")
}
the last bit of output of that is:
f1: 0.006ms f2: 0.06ms f3: 0.053ms
which means that it took 0.06 milliseconds for structuredClone to make a convenient deep copy of an object that is 5KB as a JSON string.
Conclusion
Yes Object.assign({}, ...) is ridiculously faster than structuredClone but structuredClone is a better choice.
Hello-world server in Bun vs Fastify
September 9, 2023
4 comments Node, JavaScript, Bun
Bun 1.0 just launched and I'm genuinely impressed and intrigued. How long can this madness keep going? I've never built anything substantial with Bun. Just various scripts to get a feel for it.
At work, I recently launched a micro-service that uses Node + Fastify + TypeScript. I'm not going to rewrite it in Bun, but I'm going to get a feel for the difference.
Basic version in Bun
No need for a package.json at this point. And that's neat. Create a src/index.ts and put this in:
const PORT = parseInt(process.env.PORT || "3000");
Bun.serve({
port: PORT,
fetch(req) {
const url = new URL(req.url);
if (url.pathname === "/") return new Response(`Home page!`);
if (url.pathname === "/json") return Response.json({ hello: "world" });
return new Response(`404!`);
},
});
console.log(`Listening on port ${PORT}`);
What's so cool about the convenience-oriented developer experience of Bun is that it comes with a native way for restarting the server as you're editing the server code:
❯ bun --hot src/index.ts
Listening on port 3000
Let's test it:
❯ xh http://localhost:3000/
HTTP/1.1 200 OK
Content-Length: 10
Content-Type: text/plain;charset=utf-8
Date: Sat, 09 Sep 2023 02:34:29 GMT
Home page!
❯ xh http://localhost:3000/json
HTTP/1.1 200 OK
Content-Length: 17
Content-Type: application/json;charset=utf-8
Date: Sat, 09 Sep 2023 02:34:35 GMT
{
"hello": "world"
}
Basic version with Node + Fastify + TypeScript
First of all, you'll need to create a package.json to install the dependencies, all of which, at this gentle point are built into Bun:
❯ npm i -D ts-node typescript @types/node nodemon
❯ npm i fastify
And edit the package.json with some scripts:
"scripts": {
"dev": "nodemon src/index.ts",
"start": "ts-node src/index.ts"
},
And of course, the code itself (src/index.ts):
import fastify from "fastify";
const PORT = parseInt(process.env.PORT || "3000");
const server = fastify();
server.get("/", async () => {
return "Home page!";
});
server.get("/json", (request, reply) => {
reply.send({ hello: "world" });
});
server.listen({ port: PORT }, (err, address) => {
if (err) {
console.error(err);
process.exit(1);
}
console.log(`Server listening at ${address}`);
});
Now run it:
❯ npm run dev
> fastify-hello-world@1.0.0 dev
> nodemon src/index.ts
[nodemon] 3.0.1
[nodemon] to restart at any time, enter `rs`
[nodemon] watching path(s): *.*
[nodemon] watching extensions: ts,json
[nodemon] starting `ts-node src/index.ts`
Server listening at http://[::1]:3000
Let's test it:
❯ xh http://localhost:3000/
HTTP/1.1 200 OK
Connection: keep-alive
Content-Length: 10
Content-Type: text/plain; charset=utf-8
Date: Sat, 09 Sep 2023 02:42:46 GMT
Keep-Alive: timeout=72
Home page!
❯ xh http://localhost:3000/json
HTTP/1.1 200 OK
Connection: keep-alive
Content-Length: 17
Content-Type: application/json; charset=utf-8
Date: Sat, 09 Sep 2023 02:43:08 GMT
Keep-Alive: timeout=72
{
"hello": "world"
}
For the record, I quite like this little setup. nodemon can automatically understand TypeScript. It's a neat minimum if Node is a desire.
Quick benchmark
Bun
Note that this server has no logging or any I/O.
❯ bun src/index.ts
Listening on port 3000
Using hey to test 10,000 requests across 100 concurrent clients:
❯ hey -n 10000 -c 100 http://localhost:3000/ Summary: Total: 0.2746 secs Slowest: 0.0167 secs Fastest: 0.0002 secs Average: 0.0026 secs Requests/sec: 36418.8132 Total data: 100000 bytes Size/request: 10 bytes
Node + Fastify
❯ npm run start
Using hey again:
❯ hey -n 10000 -c 100 http://localhost:3000/ Summary: Total: 0.6606 secs Slowest: 0.0483 secs Fastest: 0.0001 secs Average: 0.0065 secs Requests/sec: 15138.5719 Total data: 100000 bytes Size/request: 10 bytes
About a 2x advantage to Bun.
Serving an HTML file with Bun
Bun.serve({
port: PORT,
fetch(req) {
const url = new URL(req.url);
if (url.pathname === "/") return new Response(`Home page!`);
if (url.pathname === "/json") return Response.json({ hello: "world" });
+ if (url.pathname === "/index.html")
+ return new Response(Bun.file("src/index.html"));
return new Response(`404!`);
},
});
Serves the src/index.html file just right:
❯ xh --headers http://localhost:3000/index.html
HTTP/1.1 200 OK
Content-Length: 889
Content-Type: text/html;charset=utf-8
Serving an HTML file with Node + Fastify
First, install the plugin:
❯ npm i @fastify/static
And make this change:
+import path from "node:path";
+
import fastify from "fastify";
+import fastifyStatic from "@fastify/static";
const PORT = parseInt(process.env.PORT || "3000");
const server = fastify();
+server.register(fastifyStatic, {
+ root: path.resolve("src"),
+});
+
server.get("/", async () => {
return "Home page!";
});
server.get("/json", (request, reply) => {
reply.send({ hello: "world" });
});
+server.get("/index.html", (request, reply) => {
+ reply.sendFile("index.html");
+});
+
server.listen({ port: PORT }, (err, address) => {
if (err) {
console.error(err);
And it works great:
❯ xh --headers http://localhost:3000/index.html
HTTP/1.1 200 OK
Accept-Ranges: bytes
Cache-Control: public, max-age=0
Connection: keep-alive
Content-Length: 889
Content-Type: text/html; charset=UTF-8
Date: Sat, 09 Sep 2023 03:04:15 GMT
Etag: W/"379-18a77e4e346"
Keep-Alive: timeout=72
Last-Modified: Sat, 09 Sep 2023 03:03:23 GMT
Quick benchmark of serving the HTML file
Bun
❯ hey -n 10000 -c 100 http://localhost:3000/index.html
Summary:
Total: 0.6408 secs
Slowest: 0.0160 secs
Fastest: 0.0001 secs
Average: 0.0063 secs
Requests/sec: 15605.9735
Total data: 8890000 bytes
Size/request: 889 bytes
Node + Fastify
❯ hey -n 10000 -c 100 http://localhost:3000/index.html
Summary:
Total: 1.5473 secs
Slowest: 0.0272 secs
Fastest: 0.0078 secs
Average: 0.0154 secs
Requests/sec: 6462.9597
Total data: 8890000 bytes
Size/request: 889 bytes
Again, a 2x performance win for Bun.
Conclusion
There isn't much to conclude here. Just an intro to the beauty of how quick Bun is, both in terms of developer experience and raw performance.
What I admire about Bun being such a convenient bundle is that Python'esque feeling of simplicity and minimalism. (For example python3.11 -m http.server -d src 3000 will make http://localhost:3000/index.html work)
The basic boilerplate of Node with Fastify + TypeScript + nodemon + ts-node is a great one if you're not ready to make the leap to Bun. I would certainly use it again. Fastify might not be the fastest server in the Node ecosystem, but it's good enough.
What's not shown in this little intro blog post, and is perhaps a silly thing to focus on, is the speed with which you type bun --hot src/index.ts and the server is ready to go. It's as far as human perception goes instant. The npm run dev on the other hand has this ~3 second "lag". Not everyone cares about that, but I do. It's more of an ethos. It's that wonderful feeling that you don't pause your thinking.

It's hard to see when I press the Enter key but compare that to Bun:
UPDATE (Sep 11, 2023)
I found this: github.com/SaltyAom/bun-http-framework-benchmark
It's a much better benchmark than mine here. Mind you, as long as you're not using something horribly slow, and you're not doing any I/O the HTTP framework performances don't matter much.